Act 1 • 0:00 – 0:15
The Hook: The Trap
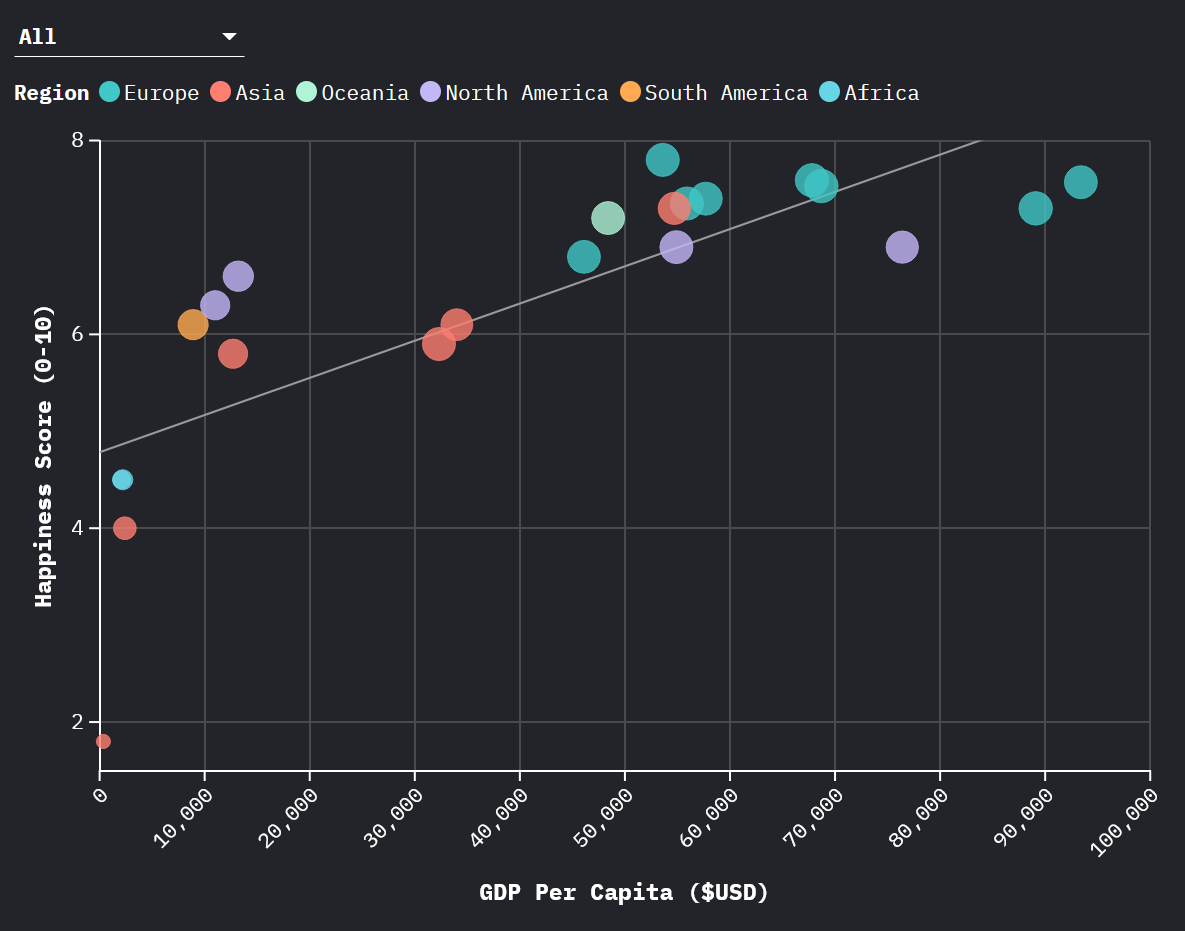
We show you a chart. You’ll draw a conclusion. And you’ll be wrong. That’s the point.
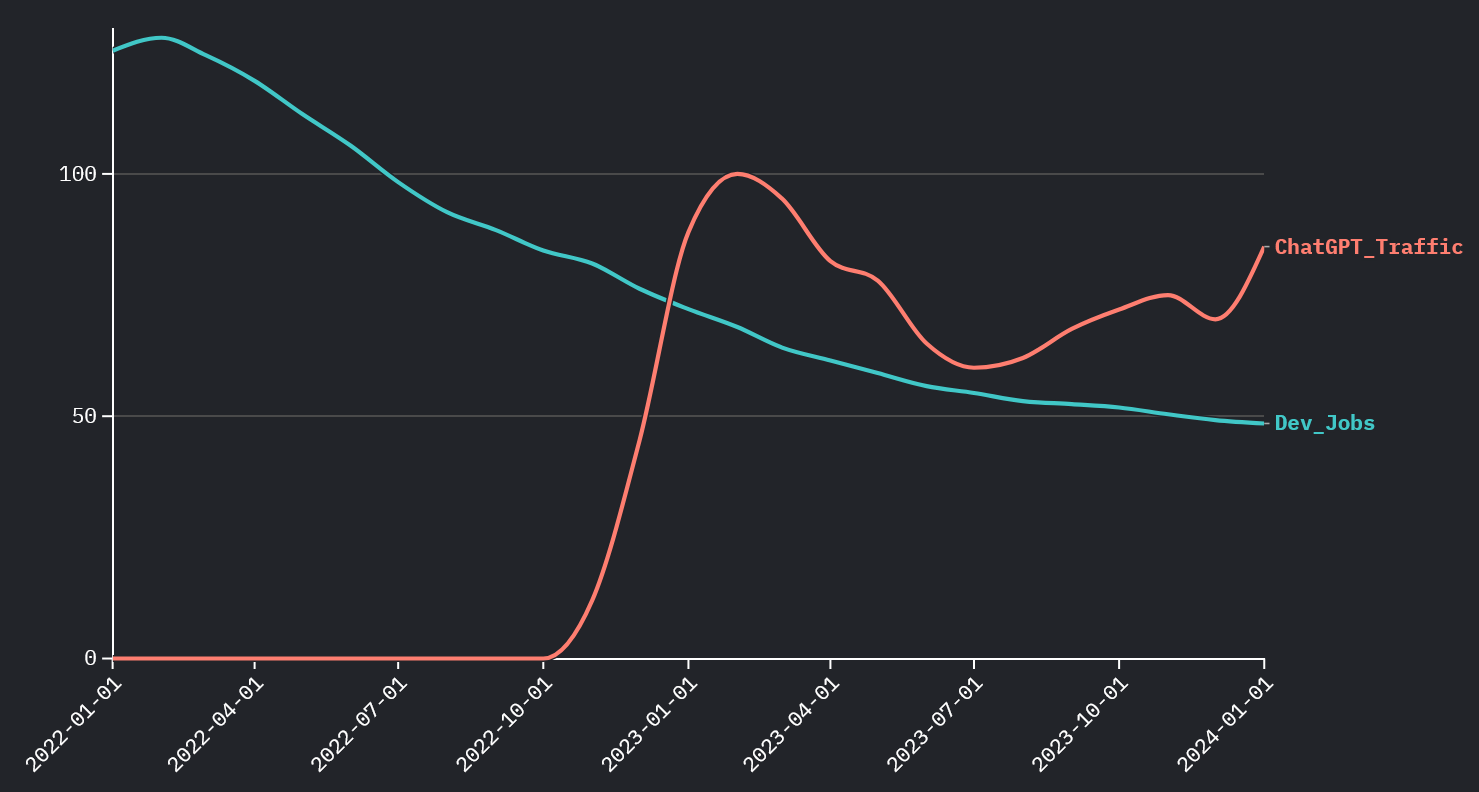
🚩 The Trap
Dev Jobs vs. ChatGPT Traffic
As ChatGPT usage rises, dev job postings plummet. Obvious conclusion: “AI is killing jobs.” But is it?
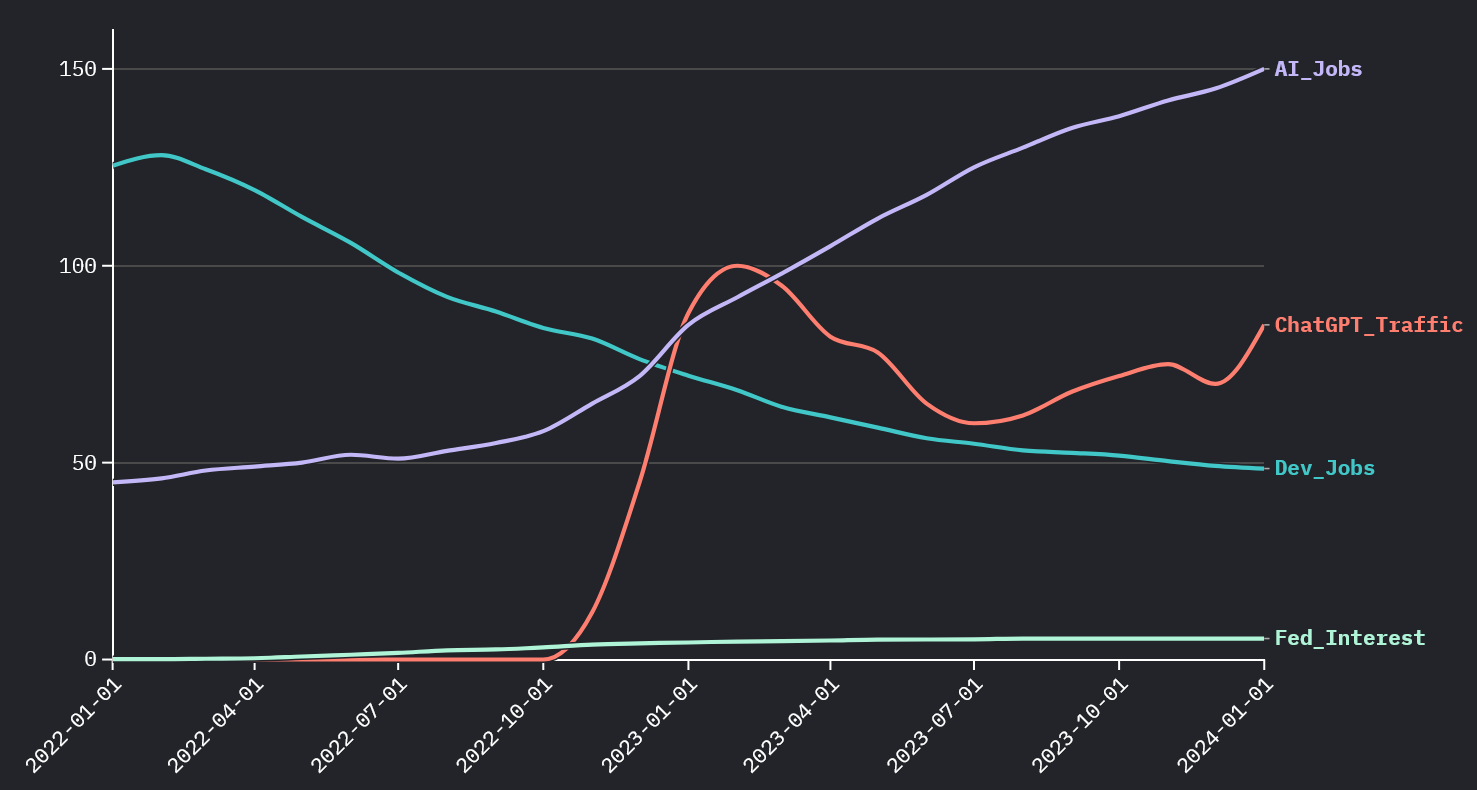
✅ The Truth
Dev Jobs vs. Federal Interest Rate
The real driver: as interest rates climbed from 0% to 5.3%, venture capital dried up and hiring froze. Timing ≠ causation.
💡 The Lesson
ChatGPT launched in November 2022 — the exact same period rates spiked. Two things happened simultaneously, but only one caused the hiring freeze. The Scientist asks: “What’s the mechanism?”
Interest rates ↑ → Venture capital dries up → Startups freeze hiring → Big Tech follows with layoffs. ChatGPT? Coincidence, not causation.
1Recreate “The Trap” in Flourish
Open Flourish: Go to flourish.studio and create a new “Line chart” visualization.
Upload Data: Import
tech_hiring_macro_trends.csv. Set Date as X-axis.Configure Series: Add Dev_Jobs as the first line (red, solid). Add ChatGPT_Traffic as a second line (green, dashed). Use a secondary Y-axis for ChatGPT.
Title It Like a Headline: Use “Did AI Kill the Entry-Level Job?” — not “Line Chart of Data.”
Now Swap It: Remove ChatGPT_Traffic. Add Fed_Interest instead (blue, dotted). Watch the narrative flip entirely.
1Recreate “The Trap” in Python
Copy-paste this into a Jupyter notebook or Python file. Requires pandas, plotly.
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
df = pd.read_csv("data/tech_hiring_macro_trends.csv", parse_dates=["Date"])
# THE TRAP: Dev Jobs vs ChatGPT
fig = make_subplots(specs=[[{"secondary_y": True}]])
fig.add_trace(go.Scatter(x=df["Date"], y=df["Dev_Jobs"],
name="Dev Job Postings", line=dict(color="#ef4444", width=3)), secondary_y=False)
fig.add_trace(go.Scatter(x=df["Date"], y=df["ChatGPT_Traffic"],
name="ChatGPT Interest", line=dict(color="#22c55e", width=3, dash="dash")), secondary_y=True)
fig.update_layout(title="The Trap: Did AI Kill the Entry-Level Job?",
template="plotly_dark", paper_bgcolor="#0f172a", plot_bgcolor="#0f172a",
hovermode="x unified", legend=dict(orientation="h", y=-0.15))
fig.show()# THE TRUTH: Dev Jobs vs Interest Rate
fig2 = make_subplots(specs=[[{"secondary_y": True}]])
fig2.add_trace(go.Scatter(x=df["Date"], y=df["Dev_Jobs"],
name="Dev Job Postings", line=dict(color="#ef4444", width=3)), secondary_y=False)
fig2.add_trace(go.Scatter(x=df["Date"], y=df["Fed_Interest"],
name="Fed Interest Rate (%)", line=dict(color="#3b82f6", width=3, dash="dot")), secondary_y=True)
fig2.update_layout(title="The Truth: Interest Rates Drove the Hiring Freeze",
template="plotly_dark", paper_bgcolor="#0f172a", plot_bgcolor="#0f172a",
hovermode="x unified", legend=dict(orientation="h", y=-0.15))
fig2.show()